在數字化浪潮奔涌的當下,云環境已成為技術創新與應用拓展的關鍵陣地。大型語言模型(LLMs)憑借其強大的語言理解與生成能力,在云環境中得到了越來越廣泛的應用,從智能客服的高效交互到內容創作的智能輔助,從智能翻譯的精準輸出到數據分析的智能洞察,LLMs 正深刻改變著各行各業的運營模式與服務體驗。然而,隨著 LLMs 應用的深度與廣度不斷拓展,一系列嚴峻的安全問題也隨之浮出水面,尤其是模型機密性和數據隱私方面的隱患,如同一把高懸的達摩克利斯之劍,給行業的健康發展帶來了巨大挑戰。
現有基于 CPU 的 TEE 實現,在面對 LLMs 推理和訓練時卻顯得力不從心。LLMs 的推理和訓練過程涉及海量數據的處理與復雜運算,對計算資源的需求呈指數級增長。傳統基于 CPU 的 TEE,由于其計算能力的局限,難以滿足如此高強度的資源需求,在處理速度和效率上無法達到理想狀態,這在一定程度上限制了 LLMs 在安全環境下的廣泛應用與進一步發展。
面對這一困境,微云全息(NASDAQ: HOLO)憑借其敏銳的技術洞察力與勇于探索的創新精神,開展了一項具有開創性的研究工作。首次在支持 TEE 的機密計算環境中對 DeepSeek 模型進行全面評估,特別引入了 Intel Trust Domain Extensions(TDX)技術,為解決問題開辟了新的路徑。
在研究過程中,微云全息對 DeepSeek 模型在純 CPU、CPU - GPU 混合和基于 TEE 的不同實現方式下的性能,展開了嚴謹且全面的基準測試。測試結果令人振奮:對于較小的參數集,如 DeepSeek - R1 - 1.5B,基于 TDX 的實現在安全環境中執行計算時,性能表現顯著優于傳統的 CPU 版本。這一發現意義非凡,它充分證明了即使在資源受限的系統中,借助 TDX 技術,依然能夠在保障數據安全與模型機密性的同時,高效地部署 LLM 模型,為那些對安全性要求極高且資源有限的應用場景帶來了新的希望。
通過進一步深入分析不同模型大小下的性能數據,微云全息發現 GPU 與 CPU 的整體性能比平均達到 12,并且較小的模型呈現出相對較低的比率。這一精準的數據為優化計算資源的配置提供了關鍵依據,有助于開發者在實際應用中,根據不同模型的特點,更加科學合理地分配 CPU 和 GPU 資源,從而顯著提升計算效率,降低計算成本。
此外,微云全息的研究并不僅限于性能測試,還深入到優化 CPU - GPU 機密計算解決方案的層面,為實現可擴展和安全的 AI 部署提供了寶貴的基礎見解和指導。這些見解和指導涵蓋了從硬件資源的巧妙搭配,到軟 件算法的精細優化,再到系統架構的合理設計等多個關鍵方面,為構建高效、安全且可擴展的 AI 計算環境提供了一套全面且系統的思路。
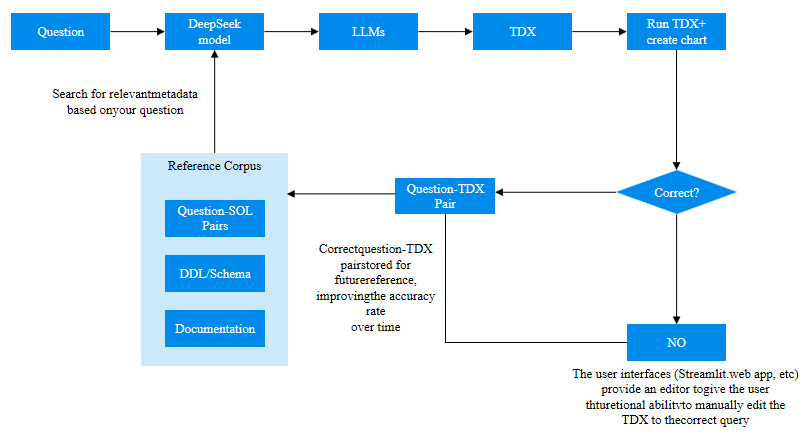
微云全息(NASDAQ: HOLO)通過在機密計算環境中對 DeepSeek 模型的深入研究與實踐,為在同樣環境下進行高效和安全的 LLMs 推理奠定了堅實基礎。未來,有望在更多領域實現安全與效率并重的 AI 部署,助力各行業在嚴守數據隱私和模型機密的前提下,充分釋放 LLMs 的巨大潛力,推動行業向智能化、安全化的方向加速邁進。

原標題:微云全息(NASDAQ: HOLO)解鎖 LLMs 安全計算密碼:TDX 賦能 DeepSeek 模型高效部署




 廣告
廣告




 廣告
廣告

 廣告
廣告


